

代码拉取完成,页面将自动刷新


To use Apache Kafka binder, you need to add spring-cloud-stream-binder-kafka as a dependency to your Spring Cloud Stream application, as shown in the following example for Maven:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
</dependency>
Alternatively, you can also use the Spring Cloud Stream Kafka Starter, as shown in the following example for Maven:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>
The following image shows a simplified diagram of how the Apache Kafka binder operates:
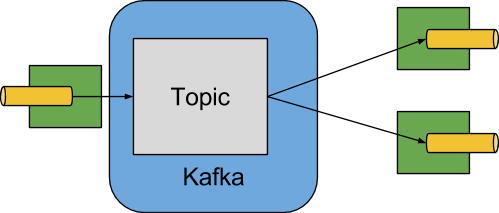
The Apache Kafka Binder implementation maps each destination to an Apache Kafka topic. The consumer group maps directly to the same Apache Kafka concept. Partitioning also maps directly to Apache Kafka partitions as well.
The binder currently uses the Apache Kafka kafka-clients version 2.3.1.
This client can communicate with older brokers (see the Kafka documentation), but certain features may not be available.
For example, with versions earlier than 0.11.x.x, native headers are not supported.
Also, 0.11.x.x does not support the autoAddPartitions property.
This section contains the configuration options used by the Apache Kafka binder.
For common configuration options and properties pertaining to binder, see the core documentation.
A list of brokers to which the Kafka binder connects.
Default: localhost.
brokers allows hosts specified with or without port information (for example, host1,host2:port2).
This sets the default port when no port is configured in the broker list.
Default: 9092.
Key/Value map of client properties (both producers and consumer) passed to all clients created by the binder. Due to the fact that these properties are used by both producers and consumers, usage should be restricted to common properties — for example, security settings. Unknown Kafka producer or consumer properties provided through this configuration are filtered out and not allowed to propagate. Properties here supersede any properties set in boot.
Default: Empty map.
Key/Value map of arbitrary Kafka client consumer properties.
In addition to support known Kafka consumer properties, unknown consumer properties are allowed here as well.
Properties here supersede any properties set in boot and in the configuration property above.
Default: Empty map.
The list of custom headers that are transported by the binder.
Only required when communicating with older applications (⇐ 1.3.x) with a kafka-clients version < 0.11.0.0. Newer versions support headers natively.
Default: empty.
The time to wait to get partition information, in seconds. Health reports as down if this timer expires.
Default: 10.
The number of required acks on the broker.
See the Kafka documentation for the producer acks property.
Default: 1.
Effective only if autoCreateTopics or autoAddPartitions is set.
The global minimum number of partitions that the binder configures on topics on which it produces or consumes data.
It can be superseded by the partitionCount setting of the producer or by the value of instanceCount * concurrency settings of the producer (if either is larger).
Default: 1.
Key/Value map of arbitrary Kafka client producer properties.
In addition to support known Kafka producer properties, unknown producer properties are allowed here as well.
Properties here supersede any properties set in boot and in the configuration property above.
Default: Empty map.
The replication factor of auto-created topics if autoCreateTopics is active.
Can be overridden on each binding.
Default: 1.
If set to true, the binder creates new topics automatically.
If set to false, the binder relies on the topics being already configured.
In the latter case, if the topics do not exist, the binder fails to start.
|
Note
|
This setting is independent of the auto.create.topics.enable setting of the broker and does not influence it.
If the server is set to auto-create topics, they may be created as part of the metadata retrieval request, with default broker settings.
|
Default: true.
If set to true, the binder creates new partitions if required.
If set to false, the binder relies on the partition size of the topic being already configured.
If the partition count of the target topic is smaller than the expected value, the binder fails to start.
Default: false.
Enables transactions in the binder. See transaction.id in the Kafka documentation and Transactions in the spring-kafka documentation.
When transactions are enabled, individual producer properties are ignored and all producers use the spring.cloud.stream.kafka.binder.transaction.producer.* properties.
Default null (no transactions)
Global producer properties for producers in a transactional binder.
See spring.cloud.stream.kafka.binder.transaction.transactionIdPrefix and Kafka Producer Properties and the general producer properties supported by all binders.
Default: See individual producer properties.
The bean name of a KafkaHeaderMapper used for mapping spring-messaging headers to and from Kafka headers.
Use this, for example, if you wish to customize the trusted packages in a BinderHeaderMapper bean that uses JSON deserialization for the headers.
If this custom BinderHeaderMapper bean is not made available to the binder using this property, then the binder will look for a header mapper bean with the name kafkaBinderHeaderMapper that is of type BinderHeaderMapper before falling back to a default BinderHeaderMapper created by the binder.
Default: none.
|
Note
|
To avoid repetition, Spring Cloud Stream supports setting values for all channels, in the format of spring.cloud.stream.kafka.default.consumer.<property>=<value>.
|
The following properties are available for Kafka consumers only and
must be prefixed with spring.cloud.stream.kafka.bindings.<channelName>.consumer..
Since version 2.1.1, this property is deprecated in favor of topic.properties, and support for it will be removed in a future version.
Since version 2.1.1, this property is deprecated in favor of topic.replicas-assignment, and support for it will be removed in a future version.
Since version 2.1.1, this property is deprecated in favor of topic.replication-factor, and support for it will be removed in a future version.
When true, topic partitions is automatically rebalanced between the members of a consumer group.
When false, each consumer is assigned a fixed set of partitions based on spring.cloud.stream.instanceCount and spring.cloud.stream.instanceIndex.
This requires both the spring.cloud.stream.instanceCount and spring.cloud.stream.instanceIndex properties to be set appropriately on each launched instance.
The value of the spring.cloud.stream.instanceCount property must typically be greater than 1 in this case.
Default: true.
When autoCommitOffset is true, this setting dictates whether to commit the offset after each record is processed.
By default, offsets are committed after all records in the batch of records returned by consumer.poll() have been processed.
The number of records returned by a poll can be controlled with the max.poll.records Kafka property, which is set through the consumer configuration property.
Setting this to true may cause a degradation in performance, but doing so reduces the likelihood of redelivered records when a failure occurs.
Also, see the binder requiredAcks property, which also affects the performance of committing offsets.
Default: false.
Whether to autocommit offsets when a message has been processed.
If set to false, a header with the key kafka_acknowledgment of the type org.springframework.kafka.support.Acknowledgment header is present in the inbound message.
Applications may use this header for acknowledging messages.
See the examples section for details.
When this property is set to false, Kafka binder sets the ack mode to org.springframework.kafka.listener.AbstractMessageListenerContainer.AckMode.MANUAL and the application is responsible for acknowledging records.
Also see ackEachRecord.
Default: true.
Effective only if autoCommitOffset is set to true.
If set to false, it suppresses auto-commits for messages that result in errors and commits only for successful messages. It allows a stream to automatically replay from the last successfully processed message, in case of persistent failures.
If set to true, it always auto-commits (if auto-commit is enabled).
If not set (the default), it effectively has the same value as enableDlq, auto-committing erroneous messages if they are sent to a DLQ and not committing them otherwise.
Default: not set.
Whether to reset offsets on the consumer to the value provided by startOffset.
Must be false if a KafkaRebalanceListener is provided; see Using a KafkaRebalanceListener.
Default: false.
The starting offset for new groups.
Allowed values: earliest and latest.
If the consumer group is set explicitly for the consumer 'binding' (through spring.cloud.stream.bindings.<channelName>.group), 'startOffset' is set to earliest. Otherwise, it is set to latest for the anonymous consumer group.
Also see resetOffsets (earlier in this list).
Default: null (equivalent to earliest).
When set to true, it enables DLQ behavior for the consumer.
By default, messages that result in errors are forwarded to a topic named error.<destination>.<group>.
The DLQ topic name can be configurable by setting the dlqName property.
This provides an alternative option to the more common Kafka replay scenario for the case when the number of errors is relatively small and replaying the entire original topic may be too cumbersome.
See [kafka-dlq-processing] processing for more information.
Starting with version 2.0, messages sent to the DLQ topic are enhanced with the following headers: x-original-topic, x-exception-message, and x-exception-stacktrace as byte[].
By default, a failed record is sent to the same partition number in the DLQ topic as the original record.
See [dlq-partition-selection] for how to change that behavior.
Not allowed when destinationIsPattern is true.
Default: false.
When enableDlq is true, and this property is not set, a dead letter topic with the same number of partitions as the primary topic(s) is created.
Usually, dead-letter records are sent to the same partition in the dead-letter topic as the original record.
This behavior can be changed; see [dlq-partition-selection].
If this property is set to 1 and there is no DqlPartitionFunction bean, all dead-letter records will be written to partition 0.
If this property is greater than 1, you MUST provide a DlqPartitionFunction bean.
Note that the actual partition count is affected by the binder’s minPartitionCount property.
Default: none
Map with a key/value pair containing generic Kafka consumer properties.
In addition to having Kafka consumer properties, other configuration properties can be passed here.
For example some properties needed by the application such as spring.cloud.stream.kafka.bindings.input.consumer.configuration.foo=bar.
The bootstrap.servers property cannot be set here; use multi-binder support if you need to connect to multiple clusters.
Default: Empty map.
The name of the DLQ topic to receive the error messages.
Default: null (If not specified, messages that result in errors are forwarded to a topic named error.<destination>.<group>).
Using this, DLQ-specific producer properties can be set.
All the properties available through kafka producer properties can be set through this property.
When native decoding is enabled on the consumer (i.e., useNativeDecoding: true) , the application must provide corresponding key/value serializers for DLQ.
This must be provided in the form of dlqProducerProperties.configuration.key.serializer and dlqProducerProperties.configuration.value.serializer.
Default: Default Kafka producer properties.
Indicates which standard headers are populated by the inbound channel adapter.
Allowed values: none, id, timestamp, or both.
Useful if using native deserialization and the first component to receive a message needs an id (such as an aggregator that is configured to use a JDBC message store).
Default: none
The name of a bean that implements RecordMessageConverter. Used in the inbound channel adapter to replace the default MessagingMessageConverter.
Default: null
The interval, in milliseconds, between events indicating that no messages have recently been received.
Use an ApplicationListener<ListenerContainerIdleEvent> to receive these events.
See Example: Pausing and Resuming the Consumer for a usage example.
Default: 30000
When true, the destination is treated as a regular expression Pattern used to match topic names by the broker.
When true, topics are not provisioned, and enableDlq is not allowed, because the binder does not know the topic names during the provisioning phase.
Note, the time taken to detect new topics that match the pattern is controlled by the consumer property metadata.max.age.ms, which (at the time of writing) defaults to 300,000ms (5 minutes).
This can be configured using the configuration property above.
Default: false
A Map of Kafka topic properties used when provisioning new topics — for example, spring.cloud.stream.kafka.bindings.input.consumer.topic.properties.message.format.version=0.9.0.0
Default: none.
A Map<Integer, List<Integer>> of replica assignments, with the key being the partition and the value being the assignments.
Used when provisioning new topics.
See the NewTopic Javadocs in the kafka-clients jar.
Default: none.
The replication factor to use when provisioning topics. Overrides the binder-wide setting.
Ignored if replicas-assignments is present.
Default: none (the binder-wide default of 1 is used).
Timeout used for polling in pollable consumers.
Default: 5 seconds.
Bean name of a KafkaAwareTransactionManager used to override the binder’s transaction manager for this binding.
Usually needed if you want to synchronize another transaction with the Kafka transaction, using the ChainedKafkaTransactionManaager.
To achieve exactly once consumption and production of records, the consumer and producer bindings must all be configured with the same transaction manager.
Default: none.
Starting with version 3.0, when spring.cloud.stream.binding.<name>.consumer.batch-mode is set to true, all of the records received by polling the Kafka Consumer will be presented as a List<?> to the listener method.
Otherwise, the method will be called with one record at a time.
The size of the batch is controlled by Kafka consumer properties max.poll.records, min.fetch.bytes, fetch.max.wait.ms; refer to the Kafka documentation for more information.
Bear in mind that batch mode is not supported with @StreamListener - it only works with the newer functional programming model.
|
Important
|
Retry within the binder is not supported when using batch mode, so maxAttempts will be overridden to 1.
You can configure a SeekToCurrentBatchErrorHandler (using a ListenerContainerCustomizer) to achieve similar functionality to retry in the binder.
You can also use a manual AckMode and call Ackowledgment.nack(index, sleep) to commit the offsets for a partial batch and have the remaining records redelivered.
Refer to the Spring for Apache Kafka documentation for more information about these techniques.
|
|
Note
|
To avoid repetition, Spring Cloud Stream supports setting values for all channels, in the format of spring.cloud.stream.kafka.default.producer.<property>=<value>.
|
The following properties are available for Kafka producers only and
must be prefixed with spring.cloud.stream.kafka.bindings.<channelName>.producer..
Since version 2.1.1, this property is deprecated in favor of topic.properties, and support for it will be removed in a future version.
Since version 2.1.1, this property is deprecated in favor of topic.replicas-assignment, and support for it will be removed in a future version.
Since version 2.1.1, this property is deprecated in favor of topic.replication-factor, and support for it will be removed in a future version.
Upper limit, in bytes, of how much data the Kafka producer attempts to batch before sending.
Default: 16384.
Whether the producer is synchronous.
Default: false.
A SpEL expression evaluated against the outgoing message used to evaluate the time to wait for ack when synchronous publish is enabled — for example, headers['mySendTimeout'].
The value of the timeout is in milliseconds.
With versions before 3.0, the payload could not be used unless native encoding was being used because, by the time this expression was evaluated, the payload was already in the form of a byte[].
Now, the expression is evaluated before the payload is converted.
Default: none.
How long the producer waits to allow more messages to accumulate in the same batch before sending the messages. (Normally, the producer does not wait at all and simply sends all the messages that accumulated while the previous send was in progress.) A non-zero value may increase throughput at the expense of latency.
Default: 0.
A SpEL expression evaluated against the outgoing message used to populate the key of the produced Kafka message — for example, headers['myKey'].
With versions before 3.0, the payload could not be used unless native encoding was being used because, by the time this expression was evaluated, the payload was already in the form of a byte[].
Now, the expression is evaluated before the payload is converted.
Default: none.
A comma-delimited list of simple patterns to match Spring messaging headers to be mapped to the Kafka Headers in the ProducerRecord.
Patterns can begin or end with the wildcard character (asterisk).
Patterns can be negated by prefixing with !.
Matching stops after the first match (positive or negative).
For example !ask,as* will pass ash but not ask.
id and timestamp are never mapped.
Default: * (all headers - except the id and timestamp)
Map with a key/value pair containing generic Kafka producer properties.
The bootstrap.servers property cannot be set here; use multi-binder support if you need to connect to multiple clusters.
Default: Empty map.
A Map of Kafka topic properties used when provisioning new topics — for example, spring.cloud.stream.kafka.bindings.output.producer.topic.properties.message.format.version=0.9.0.0
A Map<Integer, List<Integer>> of replica assignments, with the key being the partition and the value being the assignments.
Used when provisioning new topics.
See the NewTopic Javadocs in the kafka-clients jar.
Default: none.
The replication factor to use when provisioning topics. Overrides the binder-wide setting.
Ignored if replicas-assignments is present.
Default: none (the binder-wide default of 1 is used).
Set to true to override the default binding destination (topic name) with the value of the KafkaHeaders.TOPIC message header in the outbound message.
If the header is not present, the default binding destination is used.
Default: false.
The bean name of a MessageChannel to which successful send results should be sent; the bean must exist in the application context.
The message sent to the channel is the sent message (after conversion, if any) with an additional header KafkaHeaders.RECORD_METADATA.
The header contains a RecordMetadata object provided by the Kafka client; it includes the partition and offset where the record was written in the topic.
ResultMetadata meta = sendResultMsg.getHeaders().get(KafkaHeaders.RECORD_METADATA, RecordMetadata.class)
Failed sends go the producer error channel (if configured); see Error Channels. Default: null
+
|
Note
|
The Kafka binder uses the partitionCount setting of the producer as a hint to create a topic with the given partition count (in conjunction with the minPartitionCount, the maximum of the two being the value being used).
Exercise caution when configuring both minPartitionCount for a binder and partitionCount for an application, as the larger value is used.
If a topic already exists with a smaller partition count and autoAddPartitions is disabled (the default), the binder fails to start.
If a topic already exists with a smaller partition count and autoAddPartitions is enabled, new partitions are added.
If a topic already exists with a larger number of partitions than the maximum of (minPartitionCount or partitionCount), the existing partition count is used.
|
Set the compression.type producer property.
Supported values are none, gzip, snappy and lz4.
If you override the kafka-clients jar to 2.1.0 (or later), as discussed in the Spring for Apache Kafka documentation, and wish to use zstd compression, use spring.cloud.stream.kafka.bindings.<binding-name>.producer.configuration.compression.type=zstd.
Default: none.
Bean name of a KafkaAwareTransactionManager used to override the binder’s transaction manager for this binding.
Usually needed if you want to synchronize another transaction with the Kafka transaction, using the ChainedKafkaTransactionManaager.
To achieve exactly once consumption and production of records, the consumer and producer bindings must all be configured with the same transaction manager.
Default: none.
Timeout in number of seconds to wait for when closing the producer.
Default: 30
In this section, we show the use of the preceding properties for specific scenarios.
autoCommitOffset to false and Relying on Manual AckingThis example illustrates how one may manually acknowledge offsets in a consumer application.
This example requires that spring.cloud.stream.kafka.bindings.input.consumer.autoCommitOffset be set to false.
Use the corresponding input channel name for your example.
@SpringBootApplication
@EnableBinding(Sink.class)
public class ManuallyAcknowdledgingConsumer {
public static void main(String[] args) {
SpringApplication.run(ManuallyAcknowdledgingConsumer.class, args);
}
@StreamListener(Sink.INPUT)
public void process(Message<?> message) {
Acknowledgment acknowledgment = message.getHeaders().get(KafkaHeaders.ACKNOWLEDGMENT, Acknowledgment.class);
if (acknowledgment != null) {
System.out.println("Acknowledgment provided");
acknowledgment.acknowledge();
}
}
}
Apache Kafka 0.9 supports secure connections between client and brokers.
To take advantage of this feature, follow the guidelines in the Apache Kafka Documentation as well as the Kafka 0.9 security guidelines from the Confluent documentation.
Use the spring.cloud.stream.kafka.binder.configuration option to set security properties for all clients created by the binder.
For example, to set security.protocol to SASL_SSL, set the following property:
spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_SSL
All the other security properties can be set in a similar manner.
When using Kerberos, follow the instructions in the reference documentation for creating and referencing the JAAS configuration.
Spring Cloud Stream supports passing JAAS configuration information to the application by using a JAAS configuration file and using Spring Boot properties.
The JAAS and (optionally) krb5 file locations can be set for Spring Cloud Stream applications by using system properties. The following example shows how to launch a Spring Cloud Stream application with SASL and Kerberos by using a JAAS configuration file:
java -Djava.security.auth.login.config=/path.to/kafka_client_jaas.conf -jar log.jar \
--spring.cloud.stream.kafka.binder.brokers=secure.server:9092 \
--spring.cloud.stream.bindings.input.destination=stream.ticktock \
--spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_PLAINTEXT
As an alternative to having a JAAS configuration file, Spring Cloud Stream provides a mechanism for setting up the JAAS configuration for Spring Cloud Stream applications by using Spring Boot properties.
The following properties can be used to configure the login context of the Kafka client:
The login module name. Not necessary to be set in normal cases.
Default: com.sun.security.auth.module.Krb5LoginModule.
The control flag of the login module.
Default: required.
Map with a key/value pair containing the login module options.
Default: Empty map.
The following example shows how to launch a Spring Cloud Stream application with SASL and Kerberos by using Spring Boot configuration properties:
java --spring.cloud.stream.kafka.binder.brokers=secure.server:9092 \
--spring.cloud.stream.bindings.input.destination=stream.ticktock \
--spring.cloud.stream.kafka.binder.autoCreateTopics=false \
--spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_PLAINTEXT \
--spring.cloud.stream.kafka.binder.jaas.options.useKeyTab=true \
--spring.cloud.stream.kafka.binder.jaas.options.storeKey=true \
--spring.cloud.stream.kafka.binder.jaas.options.keyTab=/etc/security/keytabs/kafka_client.keytab \
--spring.cloud.stream.kafka.binder.jaas.options.principal=kafka-client-1@EXAMPLE.COM
The preceding example represents the equivalent of the following JAAS file:
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/etc/security/keytabs/kafka_client.keytab"
principal="kafka-client-1@EXAMPLE.COM";
};
If the topics required already exist on the broker or will be created by an administrator, autocreation can be turned off and only client JAAS properties need to be sent.
|
Note
|
Do not mix JAAS configuration files and Spring Boot properties in the same application.
If the -Djava.security.auth.login.config system property is already present, Spring Cloud Stream ignores the Spring Boot properties.
|
|
Note
|
Be careful when using the autoCreateTopics and autoAddPartitions with Kerberos.
Usually, applications may use principals that do not have administrative rights in Kafka and Zookeeper.
Consequently, relying on Spring Cloud Stream to create/modify topics may fail.
In secure environments, we strongly recommend creating topics and managing ACLs administratively by using Kafka tooling.
|
If you wish to suspend consumption but not cause a partition rebalance, you can pause and resume the consumer.
This is facilitated by adding the Consumer as a parameter to your @StreamListener.
To resume, you need an ApplicationListener for ListenerContainerIdleEvent instances.
The frequency at which events are published is controlled by the idleEventInterval property.
Since the consumer is not thread-safe, you must call these methods on the calling thread.
The following simple application shows how to pause and resume:
@SpringBootApplication
@EnableBinding(Sink.class)
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@StreamListener(Sink.INPUT)
public void in(String in, @Header(KafkaHeaders.CONSUMER) Consumer<?, ?> consumer) {
System.out.println(in);
consumer.pause(Collections.singleton(new TopicPartition("myTopic", 0)));
}
@Bean
public ApplicationListener<ListenerContainerIdleEvent> idleListener() {
return event -> {
System.out.println(event);
if (event.getConsumer().paused().size() > 0) {
event.getConsumer().resume(event.getConsumer().paused());
}
};
}
}
Enable transactions by setting spring.cloud.stream.kafka.binder.transaction.transactionIdPrefix to a non-empty value, e.g. tx-.
When used in a processor application, the consumer starts the transaction; any records sent on the consumer thread participate in the same transaction.
When the listener exits normally, the listener container will send the offset to the transaction and commit it.
A common producer factory is used for all producer bindings configured using spring.cloud.stream.kafka.binder.transaction.producer.* properties; individual binding Kafka producer properties are ignored.
|
Important
|
Normal binder retries (and dead lettering) are not supported with transactions because the retries will run in the original transaction, which may be rolled back and any published records will be rolled back too.
When retries are enabled (the common property maxAttempts is greater than zero) the retry properties are used to configure a DefaultAfterRollbackProcessor to enable retries at the container level.
Similarly, instead of publishing dead-letter records within the transaction, this functionality is moved to the listener container, again via the DefaultAfterRollbackProcessor which runs after the main transaction has rolled back.
|
If you wish to use transactions in a source application, or from some arbitrary thread for producer-only transaction (e.g. @Scheduled method), you must get a reference to the transactional producer factory and define a KafkaTransactionManager bean using it.
@Bean
public PlatformTransactionManager transactionManager(BinderFactory binders,
@Value("${unique.tx.id.per.instance}") String txId) {
ProducerFactory<byte[], byte[]> pf = ((KafkaMessageChannelBinder) binders.getBinder(null,
MessageChannel.class)).getTransactionalProducerFactory();
KafkaTransactionManager tm = new KafkaTransactionManager<>(pf);
tm.setTransactionId(txId)
return tm;
}
Notice that we get a reference to the binder using the BinderFactory; use null in the first argument when there is only one binder configured.
If more than one binder is configured, use the binder name to get the reference.
Once we have a reference to the binder, we can obtain a reference to the ProducerFactory and create a transaction manager.
Then you would use normal Spring transaction support, e.g. TransactionTemplate or @Transactional, for example:
public static class Sender {
@Transactional
public void doInTransaction(MessageChannel output, List<String> stuffToSend) {
stuffToSend.forEach(stuff -> output.send(new GenericMessage<>(stuff)));
}
}
If you wish to synchronize producer-only transactions with those from some other transaction manager, use a ChainedTransactionManager.
|
Important
|
If you deploy multiple instances of your application, each instance needs a unique transactionIdPrefix.
|
Starting with version 1.3, the binder unconditionally sends exceptions to an error channel for each consumer destination and can also be configured to send async producer send failures to an error channel. See [spring-cloud-stream-overview-error-handling] for more information.
The payload of the ErrorMessage for a send failure is a KafkaSendFailureException with properties:
failedMessage: The Spring Messaging Message<?> that failed to be sent.
record: The raw ProducerRecord that was created from the failedMessage
There is no automatic handling of producer exceptions (such as sending to a Dead-Letter queue). You can consume these exceptions with your own Spring Integration flow.
Kafka binder module exposes the following metrics:
spring.cloud.stream.binder.kafka.offset: This metric indicates how many messages have not been yet consumed from a given binder’s topic by a given consumer group.
The metrics provided are based on the Mircometer metrics library. The metric contains the consumer group information, topic and the actual lag in committed offset from the latest offset on the topic.
This metric is particularly useful for providing auto-scaling feedback to a PaaS platform.
When using compacted topics, a record with a null value (also called a tombstone record) represents the deletion of a key.
To receive such messages in a @StreamListener method, the parameter must be marked as not required to receive a null value argument.
@StreamListener(Sink.INPUT)
public void in(@Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) byte[] key,
@Payload(required = false) Customer customer) {
// customer is null if a tombstone record
...
}
Applications may wish to seek topics/partitions to arbitrary offsets when the partitions are initially assigned, or perform other operations on the consumer.
Starting with version 2.1, if you provide a single KafkaRebalanceListener bean in the application context, it will be wired into all Kafka consumer bindings.
public interface KafkaBindingRebalanceListener {
/**
* Invoked by the container before any pending offsets are committed.
* @param bindingName the name of the binding.
* @param consumer the consumer.
* @param partitions the partitions.
*/
default void onPartitionsRevokedBeforeCommit(String bindingName, Consumer<?, ?> consumer,
Collection<TopicPartition> partitions) {
}
/**
* Invoked by the container after any pending offsets are committed.
* @param bindingName the name of the binding.
* @param consumer the consumer.
* @param partitions the partitions.
*/
default void onPartitionsRevokedAfterCommit(String bindingName, Consumer<?, ?> consumer, Collection<TopicPartition> partitions) {
}
/**
* Invoked when partitions are initially assigned or after a rebalance.
* Applications might only want to perform seek operations on an initial assignment.
* @param bindingName the name of the binding.
* @param consumer the consumer.
* @param partitions the partitions.
* @param initial true if this is the initial assignment.
*/
default void onPartitionsAssigned(String bindingName, Consumer<?, ?> consumer, Collection<TopicPartition> partitions,
boolean initial) {
}
}
You cannot set the resetOffsets consumer property to true when you provide a rebalance listener.
To build the source you will need to install JDK 1.7.
The build uses the Maven wrapper so you don’t have to install a specific version of Maven. To enable the tests, you should have Kafka server 0.9 or above running before building. See below for more information on running the servers.
The main build command is
$ ./mvnw clean install
You can also add '-DskipTests' if you like, to avoid running the tests.
|
Note
|
You can also install Maven (>=3.3.3) yourself and run the mvn command
in place of ./mvnw in the examples below. If you do that you also
might need to add -P spring if your local Maven settings do not
contain repository declarations for spring pre-release artifacts.
|
|
Note
|
Be aware that you might need to increase the amount of memory
available to Maven by setting a MAVEN_OPTS environment variable with
a value like -Xmx512m -XX:MaxPermSize=128m. We try to cover this in
the .mvn configuration, so if you find you have to do it to make a
build succeed, please raise a ticket to get the settings added to
source control.
|
The projects that require middleware generally include a
docker-compose.yml, so consider using
Docker Compose to run the middeware servers
in Docker containers.
If you don’t have an IDE preference we would recommend that you use Spring Tools Suite or Eclipse when working with the code. We use the m2eclipe eclipse plugin for maven support. Other IDEs and tools should also work without issue.
We recommend the m2eclipe eclipse plugin when working with eclipse. If you don’t already have m2eclipse installed it is available from the "eclipse marketplace".
Unfortunately m2e does not yet support Maven 3.3, so once the projects
are imported into Eclipse you will also need to tell m2eclipse to use
the .settings.xml file for the projects. If you do not do this you
may see many different errors related to the POMs in the
projects. Open your Eclipse preferences, expand the Maven
preferences, and select User Settings. In the User Settings field
click Browse and navigate to the Spring Cloud project you imported
selecting the .settings.xml file in that project. Click Apply and
then OK to save the preference changes.
|
Note
|
Alternatively you can copy the repository settings from .settings.xml into your own ~/.m2/settings.xml.
|
If you prefer not to use m2eclipse you can generate eclipse project metadata using the following command:
$ ./mvnw eclipse:eclipse
The generated eclipse projects can be imported by selecting import existing projects
from the file menu.
[[contributing]
== Contributing
Spring Cloud is released under the non-restrictive Apache 2.0 license, and follows a very standard Github development process, using Github tracker for issues and merging pull requests into master. If you want to contribute even something trivial please do not hesitate, but follow the guidelines below.
Before we accept a non-trivial patch or pull request we will need you to sign the contributor’s agreement. Signing the contributor’s agreement does not grant anyone commit rights to the main repository, but it does mean that we can accept your contributions, and you will get an author credit if we do. Active contributors might be asked to join the core team, and given the ability to merge pull requests.
None of these is essential for a pull request, but they will all help. They can also be added after the original pull request but before a merge.
Use the Spring Framework code format conventions. If you use Eclipse
you can import formatter settings using the
eclipse-code-formatter.xml file from the
Spring
Cloud Build project. If using IntelliJ, you can use the
Eclipse Code Formatter
Plugin to import the same file.
Make sure all new .java files to have a simple Javadoc class comment with at least an
@author tag identifying you, and preferably at least a paragraph on what the class is
for.
Add the ASF license header comment to all new .java files (copy from existing files
in the project)
Add yourself as an @author to the .java files that you modify substantially (more
than cosmetic changes).
Add some Javadocs and, if you change the namespace, some XSD doc elements.
A few unit tests would help a lot as well — someone has to do it.
If no-one else is using your branch, please rebase it against the current master (or other target branch in the main project).
When writing a commit message please follow these conventions,
if you are fixing an existing issue please add Fixes gh-XXXX at the end of the commit
message (where XXXX is the issue number).
此处可能存在不合适展示的内容,页面不予展示。您可通过相关编辑功能自查并修改。
如您确认内容无涉及 不当用语 / 纯广告导流 / 暴力 / 低俗色情 / 侵权 / 盗版 / 虚假 / 无价值内容或违法国家有关法律法规的内容,可点击提交进行申诉,我们将尽快为您处理。









